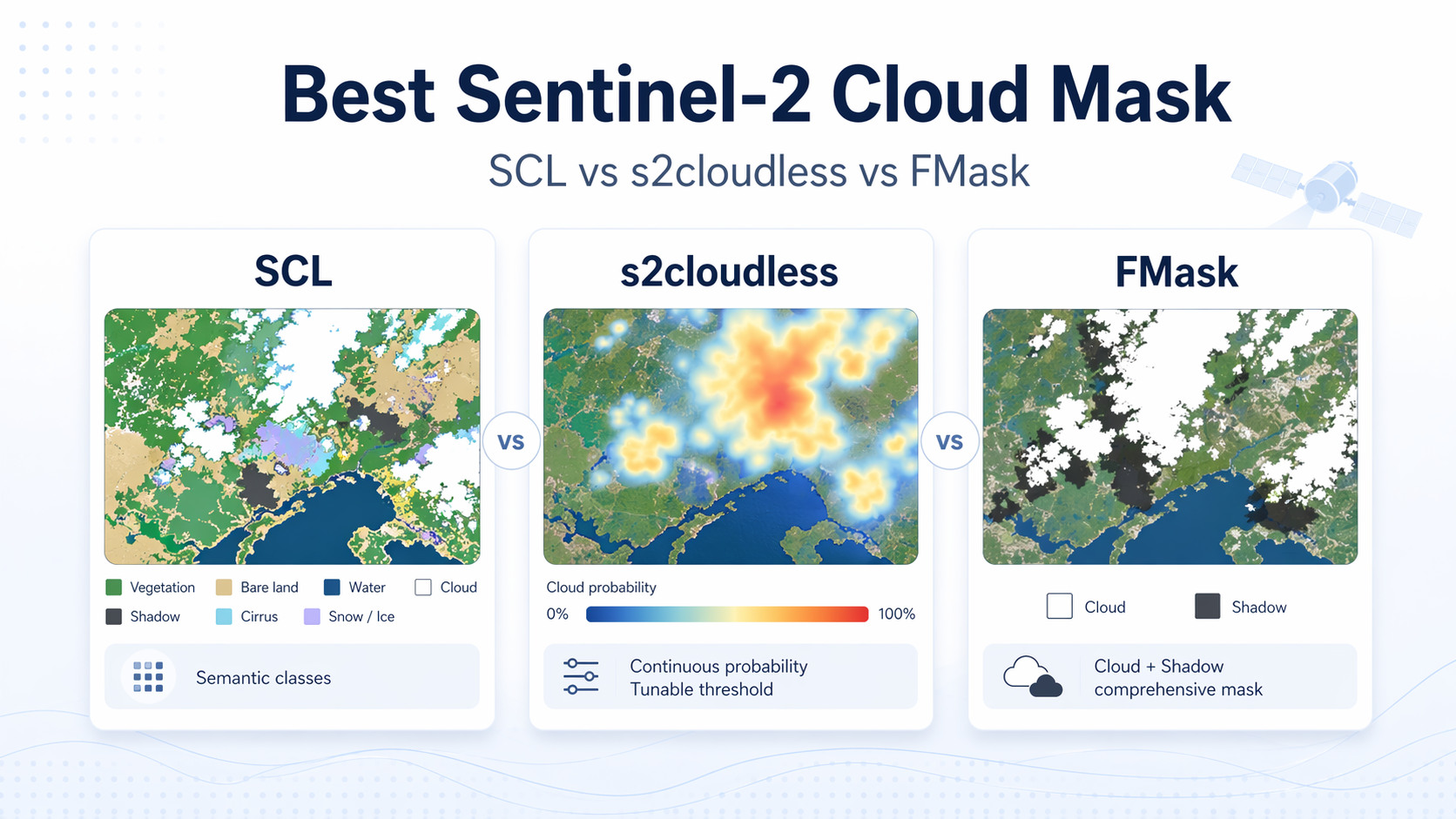
Best Sentinel-2 Cloud Mask: SCL vs s2cloudless vs FMask vs Cloud Score+
2026-03-31 · 14 min read · Sentinel-2 · Cloud Masking · Earth Observation · Near Real-Time · Cloud Score+
TL;DR: There is no universal best Sentinel-2 cloud mask. SCL is the easiest built-in quality layer, s2cloudless is a useful tunable cloud-probability model, FMask gives a fuller cloud-plus-shadow workflow, Cloud Score+ is one of the strongest public baselines for pixel usability scoring, and KappaMask/KappaMaskv2 are important AI-based baselines for cloud shadow and semi-transparent cloud. Published benchmarks show large differences between methods, but the ranking changes with the dataset, class mapping, threshold, and whether thin cloud and shadow count as unusable.
The plain-English answer
The frustrating answer is also the honest one: Asking for the “best” Sentinel-2 cloud mask mixes together tools that were built for different jobs.
Some methods answer a cloud-detection question:
Is this pixel cloudy?
Some methods answer a semantic-classification question:
Is this pixel clear, cloud, cloud shadow, cirrus, snow, water, or something else?
And some methods answer the more practical production question:
Is this observation usable?
Those are related questions, but they are not the same question. A cloud-only probability can miss cloud shadow. A semantic scene classification can be convenient but too rigid. A usability score can be excellent for compositing and time-series filtering, but may not tell you exactly why a pixel is bad.
SCL, short for Scene Classification Layer, is the easiest place to start because it arrives with many Sentinel-2 L2A (Level-2A surface reflectance) products. It is explainable, convenient, and good enough for many filtering tasks. But it is not just a standalone cloud detector. ESA’s algorithm description says the scene classification map mainly supports Sen2Cor atmospheric correction by separating cloudy pixels, clear land, and water, while also providing classes such as cloud shadow, cloud probability classes, cirrus, and snow. That makes SCL useful, but it also tells you what it was optimized for. ESA, Sentinel-2 L2A ATBD
s2cloudless is different. It is a single-scene, pixel-based cloud detector that uses Sentinel-2 bands and returns cloud probability, which you can threshold to match your tolerance for false positives or missed clouds. That probability output is the real reason people like it. You are not locked into one hard class boundary. One practical nuance matters, though: If you use hosted convenience layers instead of running the model yourself, some platforms expose precomputed cloud probability and cloud mask bands at coarser resolution, which is useful for fast screening but not identical to running the model directly. Sentinel Hub, s2cloudless repository Sentinel Hub, Cloud Masks documentation
FMask is different again. It is not just a cloud score. It is a fuller masking workflow designed to identify clouds and cloud shadows, and the current public implementation for Sentinel-2 expects L1C (Level-1C top-of-atmosphere) input and outputs explicit classes for clear land, clear water, cloud shadow, snow or ice, and cloud. That makes it attractive when shadow contamination is the real operational problem, not just cloud opacity. GERSL, FMask repository
Cloud Score+ is an important modern baseline because it is closer to a “usable pixel” score than a traditional cloud mask. Google describes Cloud Score+ as a quality assessment processor that grades Sentinel-2 pixels from 0 to 1 according to surface visibility, where 0 means not clear or occluded and 1 means clear or unoccluded. It provides two bands: cs, an instantaneous spectral-distance score, and cs_cdf, a score based on how the current observation compares with the historical distribution for that location. That makes it especially relevant for compositing and time-series workflows where the practical question is not only “is this cloud?” but “should I trust this observation?” Google Earth Engine, Cloud Score+ S2_HARMONIZED
KappaMask and KappaMaskv2 are AI-based cloud-mask processors from KappaZeta. They are worth including because they explicitly target difficult classes such as cloud shadow and semi-transparent cloud, which are often the cases that break production time series. KappaMask outputs classes such as clear, cloud shadow, semi-transparent cloud, cloud, and missing pixels. KappaZeta, KappaMask repository
What each option actually gives you
| Option | What it really is | What you get | Best fit | Main weakness |
|---|---|---|---|---|
| SCL | A Sen2Cor scene classification map inside Sentinel-2 L2A | Fixed semantic classes such as cloud shadow, medium and high probability cloud, cirrus, snow or ice, water, vegetation, not-vegetated | Fast quality assurance, explainable masking, product-native filtering | Not a tunable probability model, and not optimized as a standalone cloud detector |
| s2cloudless | A single-scene cloud probability model | Cloud probability, then a thresholded cloud mask if you choose one | Near real-time screening, tunable omission versus commission trade-offs | Cloud only, so you still need separate shadow handling |
| FMask | A cloud and cloud-shadow masking workflow | Clear land, water, cloud shadow, snow or ice, cloud | Pipelines that must solve cloud and shadow together | More moving parts, more preprocessing assumptions, and more scene-specific failure modes |
| Cloud Score+ | A Sentinel-2 pixel usability / surface-visibility score | Continuous 0–1 scores: cs and cs_cdf | Compositing, ranking observations, weighting pixels, time-series quality assurance | Not a semantic cloud taxonomy; it tells you how usable the pixel is, not always why it is bad |
| KappaMask / KappaMaskv2 | AI-based semantic cloud and shadow masking | Classes such as clear, cloud shadow, semi-transparent cloud, cloud, and missing | Workflows where cloud shadow and semi-transparent cloud matter | Benchmark numbers are not directly interchangeable with probability-score methods |
That table already hints at the answer. If your question is really “What should I use as the default mask on standard Sentinel-2 L2A imagery?”, SCL is the simplest starting point. If your question is “What gives me control over cloud aggressiveness in a single date?”, s2cloudless is useful because it gives probability rather than only hard classes. If your question is “What gives me cloud and cloud shadow in one workflow?”, FMask or KappaMask-style semantic masks become more relevant. If your question is “Which pixels are most usable for a composite or time series?”, Cloud Score+ is one of the most relevant public baselines.
Which cloud mask is best for near real-time work?
Near real-time Earth observation has asymmetric costs. A missed cloud can quietly poison downstream indices, classifications, and alerts. An extra false cloud usually just costs you one observation. Because of that asymmetry, probability and quality scores are often more useful than hard classes. They let you tune the mask to the application instead of inheriting someone else’s threshold.
That is why s2cloudless remains useful in practice. It is easy to push it conservative for alerting workflows, or relax it when coverage matters more than perfect cleanliness. It also plays well with other signals. You can combine cloud probability with view geometry, temporal consistency, or product-native quality layers instead of pretending one bitmask should settle everything.
Cloud Score+ is often a better match when the workflow is about compositing, observation ranking, or time-series filtering. It is not just asking whether a pixel looks cloudy. It is scoring whether the surface is visible enough to be useful. For workflows built around “best available observation” logic, that distinction matters.
SCL still earns its place in near real-time pipelines because it gives interpretable semantic classes with almost no extra work. Cloud shadow, cirrus, snow or ice, saturated or defective pixels, and water are all operationally useful categories. But when teams treat SCL as the final authority on cloud, they usually hit the same ceiling: It is convenient, yet not flexible enough when the scene gets ambiguous.
FMask and KappaMask-style workflows become compelling when shadow contamination matters as much as cloud detection. That is common in mountainous terrain, urban areas with strong contrast, and workflows where dark cloud shadow can be misread as water, burn severity, vegetation change, or crop stress. In those cases, a cloud-only score is not enough.
Where these methods usually break
SCL struggles most where fixed classes meet messy reality. Thin cloud edges, bright bare ground, snow transitions, coastal haze, and ambiguous cirrus are exactly where a crisp semantic label can feel overconfident. The problem is not that the map is useless. The problem is that users often ask more from it than it was meant to deliver.
s2cloudless breaks in a different way. It gives you a probability surface, which is powerful, but it does not solve the full masking problem on its own. You still need to decide how to threshold it, how much to dilate cloud edges, and how to handle shadow. If you skip those decisions, the model can look better in a demo than in an analysis pipeline.
FMask’s failure mode is complexity. Once you ask one workflow to detect cloud and then match cloud shadow geometrically, you gain useful structure but also inherit more assumptions. Input level matters, preprocessing matters, and scene geometry matters. That is why FMask can be excellent in the right pipeline and still not be the easiest default for every Sentinel-2 user.
Cloud Score+ is strong for usability scoring, but it is not a full semantic explanation of the scene. It is useful when you want to rank or filter observations, but less useful if your workflow needs to know whether the bad pixel was cloud, shadow, snow, haze, or something else.
KappaMask/KappaMaskv2 are strong baselines for semantic cloud, shadow, and semi-transparent cloud masking, but their benchmark numbers should not be mixed casually with Cloud Score+ or s2cloudless numbers. A semantic multi-class Dice score and a binary clear/not-clear F1 score are not the same measurement.
What published benchmark numbers say
Cloud-mask comparisons are notoriously sensitive to what exactly gets scored. Thick cloud cores are the easy part. Thin or semi-transparent clouds, cloud edges, shadows, snow, bright cities, bright rock, and coastal haze are where methods separate. The CMIX, short for Cloud Mask Intercomparison eXercise, found that algorithm performance varies by reference dataset and that thin or semi-transparent clouds remain harder than thick clouds. In other words: The leaderboard moves when the truth data and scoring rules move. Skakun et al., 2022, CMIX
The safest way to read published numbers is as benchmark snapshots, not a universal ranking.
| Benchmark / source | Compared methods | Metric | Reported result | What it means |
|---|---|---|---|---|
| CMIX Sentinel-2 intercomparison | Ten cloud-mask algorithms | Overall accuracy | Sentinel-2 average overall accuracy ranged from about 80.0 ± 5.3% to 89.4 ± 2.4% | There is no universal winner; results depend heavily on reference data, class definitions, and whether thin cloud is counted |
| Cloud Score+ paper, Tarrio reference dataset | Cloud Score+, FMask, MAJA, Tmask, LaSRC, s2cloudless, Sen2Cor, QA60 | Binary clear / not-clear F1 and overall accuracy | Cloud Score+ reached F1 0.8466 and overall accuracy 0.8096; s2cloudless reached F1 0.7589 and overall accuracy 0.7111; Sen2Cor reached F1 0.5190 and overall accuracy 0.5675 | Cloud Score+ is a strong public baseline for “is this observation usable?” scoring |
| Cloud Score+ paper, CMIX-I PixBox | Cloud Score+ and s2cloudless | Binary clear / not-clear F1 and overall accuracy | Cloud Score+ reached F1 0.8816 and overall accuracy 0.8768; s2cloudless reached F1 0.8162 and overall accuracy 0.8094 | In this benchmark, Cloud Score+ outperformed s2cloudless, especially when the task is clear/not-clear usability |
| KappaMask paper, KappaZeta test dataset | KappaMask L2A, KappaMask L1C, Sen2Cor, FMask, MAJA | Multi-class Dice coefficient | KappaMask L2A reached 80% all-class Dice; KappaMask L1C 76%; Sen2Cor 59%; FMask 61%; MAJA 51% | Deep learning improved cloud, cloud-shadow, and semi-transparent cloud classification on this challenging labelled dataset |
| KappaMask paper, binary clear/cloud comparison | KappaMask L2A, KappaMask L1C, s2cloudless, DL_L8S2_UV | Binary Dice coefficient | KappaMask L2A reached 84% Dice; KappaMask L1C 80%; s2cloudless 63%; DL_L8S2_UV 62% | On this test set, KappaMask performed substantially better than s2cloudless in a binary comparison |
| KappaMaskv2 / KappaSet | KappaMaskv2 vs other cloud masks | Per-class Dice coefficient | KappaMaskv2 L1C reported Dice coefficients of 67% for cloud shadow, 75% for semi-transparent cloud, and 84% for cloud | KappaMaskv2 is especially relevant when shadow and thin cloud matter, not just thick cloud cores |
These numbers should not be merged into one simple leaderboard. The Cloud Score+ results are from binary clear/not-clear scoring. The KappaMask results are from semantic segmentation datasets with classes such as clear, cloud shadow, semi-transparent cloud, and cloud. s2cloudless is mainly a cloud-probability model, so it is often disadvantaged when cloud shadow is counted as an unusable observation unless shadow handling is added separately.
That is why simplistic takes like “FMask is best” or “SCL is enough” usually age badly. They compress several choices into one slogan: product level, cloud definition, shadow handling, dilation buffer, threshold, and tolerance for omission versus commission. Once you unpack those choices, the masks stop looking interchangeable.
Practical recommendation for production workflows
For a typical Sentinel-2 L2A workflow, SCL is the best built-in quality layer, but not usually the best final cloud decision by itself. For a single-date cloud detector that you can tune to your risk tolerance, s2cloudless is a useful starting point. For a workflow that must solve cloud and cloud shadow together, especially from L1C input, FMask or KappaMask-style semantic masks become more relevant. For observation ranking, compositing, and time-series quality scoring, Cloud Score+ is one of the most important public baselines.
In production time series, a hybrid pattern is usually stronger than any single mask. Use a probability or usability score as the main quality signal, keep semantic classes for obvious bad pixels such as cloud shadow, snow, and cirrus, and then clean up remaining mistakes with temporal quality assurance (QA). That is less elegant than choosing a single winner, but it is closer to how robust pipelines actually work.
The most important production distinction is this:
Cloud masking asks whether a pixel is cloudy. Usability scoring asks whether the observation should be trusted.
For analytics, the second question is often the one that matters. A thin cloud, cloud shadow, haze, snow edge, or bad atmospheric correction can all produce a pixel that is not useful, even if the failure is not a simple thick-cloud label.
There is also a more fundamental point for time-series systems: The cleanest workflow is often the one that depends less on single-date cloud masking in the first place. At ClearSKY, our output is designed to be cloud-free, and when the workflow allows it we prefer not to use cloud masks as the primary gate on input data. That is especially true for time-series analysis, where many cloud masks are inconsistent enough to introduce temporal noise of their own. In that setting, multi-observation logic and temporal methods are often more reliable than asking any one mask to be correct everywhere on every date.
So which one should you use?
If you need a quick built-in filter, start with SCL.
If you need a tunable single-date cloud probability, use s2cloudless.
If you need explicit cloud and cloud-shadow masking, consider FMask or KappaMask/KappaMaskv2.
If you need to rank observations by how usable they are for compositing or time-series analysis, include Cloud Score+ as a serious baseline.
If you need production-grade time series, do not rely blindly on any single mask. Combine probability, semantic classes, temporal consistency, and application-specific thresholds. Better still, use workflows that reduce dependence on single-date cloud masks altogether.
FAQ
›Is SCL enough for NDVI (Normalized Difference Vegetation Index) or land-cover time series?
It is often enough for quick filtering and exploratory work. It is usually not enough for the cleanest production time series because cloud edges, thin cirrus, cloud shadow, snow transitions, and bright surfaces can still leak through or get over-masked. Teams that care about consistency over time usually add a probability layer, a usability score, temporal cleanup, or all three.
›Why do people like s2cloudless so much?
The main reason is control. A probability map lets you choose how conservative or permissive the mask should be for a specific workflow instead of accepting one fixed class boundary. That matters a lot when the cost of a missed cloud is very different from the cost of masking a usable pixel.
›How is Cloud Score+ different from s2cloudless?
s2cloudless is mainly a cloud-probability model. Cloud Score+ is closer to a pixel usability or surface-visibility score. That makes Cloud Score+ especially relevant for compositing and time-series workflows where the real question is whether the observation should be trusted, not only whether the pixel is cloudy.
›When should I prefer FMask or KappaMask over s2cloudless?
Prefer FMask or KappaMask-style methods when cloud shadow and semi-transparent cloud are first-order problems. A cloud-only probability can be useful, but it does not fully solve shadow contamination by itself. That matters in mountains, urban areas, coastal areas, and vegetation workflows where shadows can look like real surface change.
›What is the best production recipe today?
The most robust answer is rarely a single mask. Start with a probability or usability score, keep semantic classes for obvious bad pixels, and use time-series logic to remove leftovers that no single-date method catches cleanly. In some production systems, especially cloud-free time-series products, the better strategy is to reduce dependence on cloud masks altogether rather than trusting them as the main decision layer.